Call:
glm(formula = cbind(num_toxicities, num_patients - num_toxicities) ~
I(log(dose)), family = binomial(), data = dlt_data)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.3528 1.6537 -2.027 0.0426 *
I(log(dose)) 0.9309 0.6495 1.433 0.1518
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 10.159 on 5 degrees of freedom
Residual deviance: 7.476 on 4 degrees of freedom
AIC: 16.751
Number of Fisher Scoring iterations: 5Week 13: Logistic Regression & AI-assisted Workflows
Plotting the predictions
Plot on probability scale
# Probability scale
dose_grid <- tibble::tibble(dose = seq(min(dlt_data$dose), max(dlt_data$dose), length.out = 100)) |>
dplyr::mutate(p_hat = predict(fit_dose, newdata = dplyr::cur_data(), type = "response"))
ggplot(dlt_data, aes(x = dose, y = empirical_rate)) +
geom_point(size = 3, color = "#1f77b4") +
geom_line(data = dose_grid, aes(y = p_hat), color = "#d62728", linewidth = 1) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_x_log10() +
labs(title = "Probability scale",
x = "Dose A (mg)",
y = "Probability of DLT") +
theme_minimal()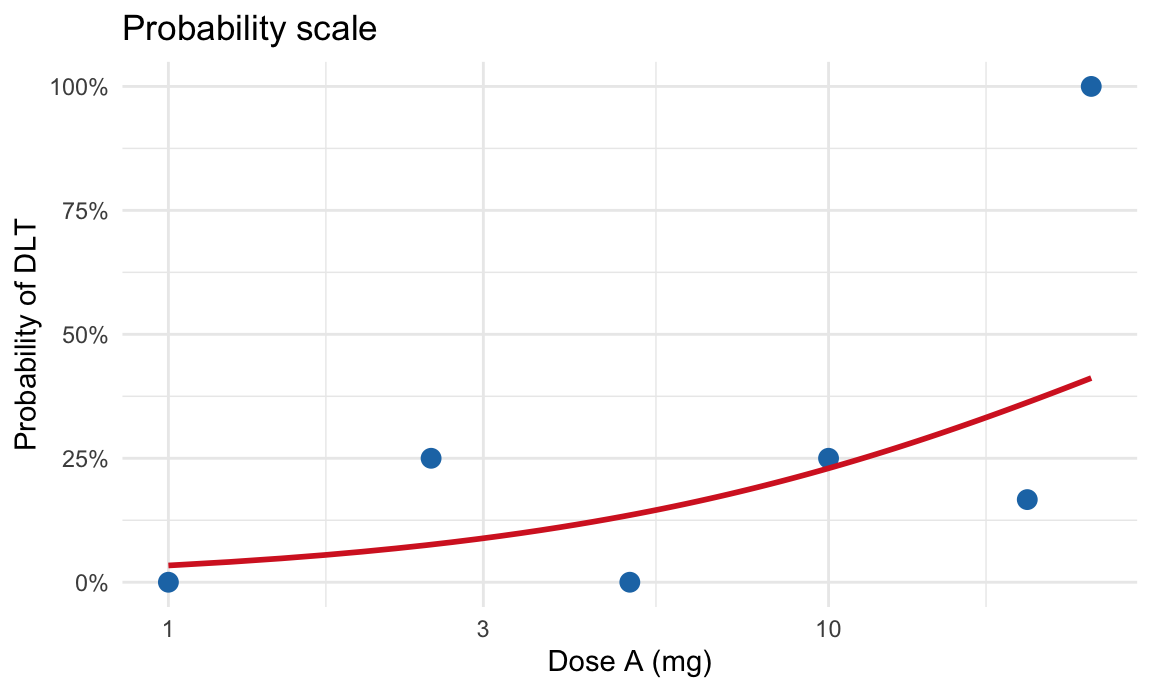
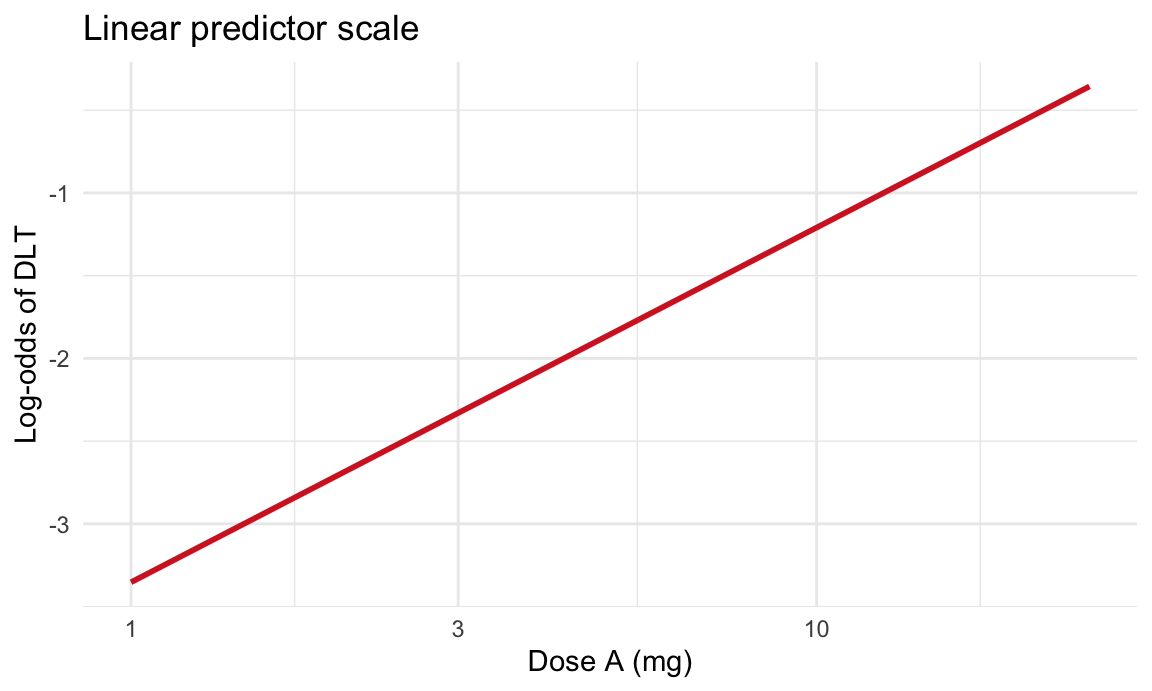
Plot on linear predictor scale
# Linear predictor (log-odds) scale
dose_grid_lp <- tibble::tibble(dose = seq(min(dlt_data$dose), max(dlt_data$dose), length.out = 100))
pred_lp <- predict(fit_dose, newdata = dose_grid_lp, type = "link", se.fit = TRUE)
dose_grid_lp$eta_hat <- as.numeric(pred_lp$fit)
ggplot(dose_grid_lp, aes(x = dose, y = eta_hat)) +
geom_line(color = "#d62728", linewidth = 1) +
scale_x_log10() +
labs(title = "Linear predictor scale",
x = "Dose A (mg)",
y = "Log-odds of DLT") +
theme_minimal()